Logging is the deliberate recording of certain information during a program execution for future reference. Logs are typically written to a log file but it is also possible to log information in other ways e.g. into a database or a remote server.
Logging can be useful for troubleshooting problems. A good logging system records some system information regularly. When bad things happen to a system e.g. an unanticipated failure, their associated log files may provide indications of what went wrong and actions can then be taken to prevent it from happening again.
A log file is like the of an airplane; they don't prevent problems but they can be helpful in understanding what went wrong after the fact.

source: https://commons.wikimedia.org
Consider two classes, Account and Guarantor, with an association as shown in the following diagram:
Example:

Here, the association is compulsory i.e. an Account object should always be linked to a Guarantor. One way to implement this is to simply use a reference variable, like this:
class Account {
Guarantor guarantor;
void setGuarantor(Guarantor g) {
guarantor = g;
}
}
However, what if someone else used the Account class like this?
Account a = new Account();
a.setGuarantor(null);
This results in an Account without a Guarantor! In a real banking system, this could have serious consequences! The code here did not try to prevent such a thing from happening. You can make the code more defensive by proactively enforcing the multiplicity constraint, like this:
class Account {
private Guarantor guarantor;
public Account(Guarantor g) {
if (g == null) {
stopSystemWithMessage(
"multiplicity violated. Null Guarantor");
}
guarantor = g;
}
public void setGuarantor(Guarantor g) {
if (g == null) {
stopSystemWithMessage(
"multiplicity violated. Null Guarantor");
}
guarantor = g;
}
// ...
}
Consider the association given below. A defensive implementation requires us to ensure that a MinedCell cannot exist without a Mine and vice versa which requires simultaneous object creation. However, Java can only create one object at a time. Given below are two alternative implementations, both of which violate the multiplicity for a short period of time.
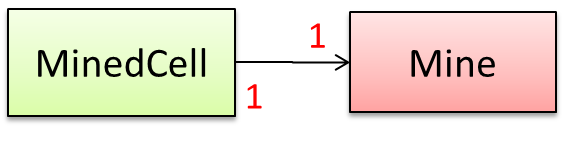
Option 1:
class MinedCell {
private Mine mine;
public MinedCell(Mine m) {
if (m == null) {
showError();
}
mine = m;
}
// ...
}
Option 1 forces us to keep a Mine without a MinedCell (until the MinedCell is created).
Option 2:
class MinedCell {
private Mine mine;
public MinedCell() {
mine = new Mine();
}
// ...
}
Option 2 is more defensive because the Mine is immediately linked to a MinedCell.
A bidirectional association in the design (shown in (a)) is usually emulated at code level using two variables (as shown in (b)).
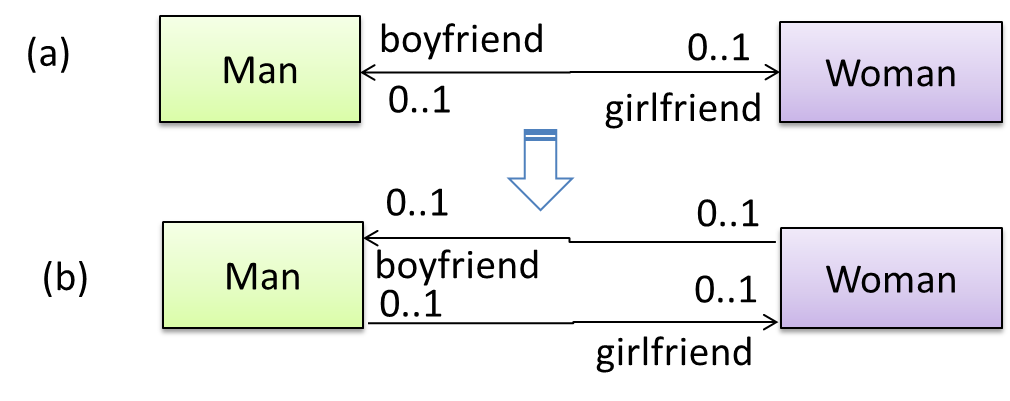
class Man {
Woman girlfriend;
void setGirlfriend(Woman w) {
girlfriend = w;
}
// ...
}
class Woman {
Man boyfriend;
void setBoyfriend(Man m) {
boyfriend = m;
}
}
The two classes are meant to be used as follows:
Woman jean;
Man james;
// ...
james.setGirlfriend(jean);
jean.setBoyfriend(james);
Suppose the two classes were used like this instead:
Woman jean;
Man james, yong;
// ...
james.setGirlfriend(jean);
jean.setBoyfriend(yong);
Now James' girlfriend is Jean, while Jean's boyfriend is not James. This situation is a result of the code not being defensive enough to stop this "love triangle". In such a situation, you could say that the referential integrity has been violated. This means that there is an inconsistency in object references.

One way to prevent this situation is to implement the two classes as shown below. Note how the referential integrity is maintained.
public class Woman {
private Man boyfriend;
public void setBoyfriend(Man m) {
if (boyfriend == m) {
return;
}
if (boyfriend != null) {
boyfriend.breakUp();
}
boyfriend = m;
m.setGirlfriend(this);
}
public void breakUp() {
boyfriend = null;
}
// ...
}
public class Man {
private Woman girlfriend;
public void setGirlfriend(Woman w) {
if (girlfriend == w) {
return;
}
if (girlfriend != null) {
girlfriend.breakUp();
}
girlfriend = w;
w.setBoyfriend(this);
}
public void breakUp() {
girlfriend = null;
}
// ...
}
When james.setGirlfriend(jean) is executed, the code ensures that james breaks up with any current girlfriend before he accepts jean as his girlfriend. Furthermore, the code ensures that jean breaks up with any existing boyfriends before accepting james as her boyfriend.